
CedrusData Catalog — новый технический каталог с поддержкой Iceberg REST API
Мы выпустили новый технический каталог для аналитических платформ, который поддерживает спецификацию Iceberg REST API. Рассказываем, зачем это нужно вам и нам

Мы выпустили CedrusData Catalog — новый технический каталог метаданных с поддержкой спецификации Iceberg REST API. В этой статье мы расскажем о нашей мотивации создания CedrusData Catalog и планах дальнейшего развития продукта.
Зачем нужен технический каталог?
Мировая индустрия использует новые способы обработки больших данных, основанные на облачных вычислениях, разделении compute и storage, и активном применении открытых форматов данных (например, Parquet, Iceberg) в дешевых облачных S3-совместимых хранилищах. Эти технические новации, совместно именуемые "lakehouse" (см. х̶а̶й̶п̶о̶в̶ы̶й̶толковый словарь Databricks), позволяют организациям быстро реализовывать новые сценарии обработки данных и снижать стоимость аналитической платформы.
Российский сектор находится в уникальном положении, обусловленном санкционным давлением и относительно слабым функционалом отечественных поставщиков. Российские компании по-прежнему вынуждены полагаться на такие технологии, как Greenplum и экосистему Hadoop (HDFS, Hive, Impala, и т.д.), которые в общемировой практике давно замещены более актуальными решениями. Для того, чтобы российские компании смогли воспользоваться преимуществами новых подходов, необходимо построить экосистему продуктов, которые используют принципы разделения compute и storage, и могут быть легко интегрированы в облачный стек.
Говоря про compute и storage, мы часто предполагаем наличие двух компонентов: хранилища (S3, HDFS) и движка (Spark, Trino, и т.п.). Но на самом деле в современном аналитическом стеке всегда присутствует и третий компонент, который объединяет первые два в полноценное решение — технический каталог.
Технический каталог хранит метаданные, необходимые вычислительному движку для работы с хранилищем. На глобальном рынке технические каталоги обычно интегрированы в продукты ведущих облачных провайдеров: Unity Catalog, AWS Glue, и т.д. В российских компаниях роль технического каталога зачастую выполняет Hive Metastore.
Проблема Hive Metastore заключается в том, что его возможности не соответствуют актуальным потребностям. Современные технические каталоги не только представляют файлы хранилища в виде логических таблиц, но и решают задачи безопасности и data governance, автоматизируют обслуживание хранилища, а также ускоряют пользовательские запросы, предоставляя движкам статистки и другие полезные метаданные. Наличие продвинутого технического каталога является важнейшим условием активной адаптации современных подходов по обработке данных.
Данные соображения привели нас к решению создать собственный технический каталог для российского рынка. Так появился CedrusData Catalog.
Почему не готовый open-source?
CedrusData Catalog разработан с "нуля", и это осознанное решение.
Как было показано выше, современные технические каталоги могут иметь широкий круг обязанностей: отображение таблиц, безопасность, производительность, и т.д. Каталоги, разрабатываемые крупными международными компаниями, ориентируются на облачный стек, который недоступен или не актуален в России. Например:
- Apache Polaris (от Snowflake) не поддерживает HDFS и имеет минимальную поддержку on-premises S3
- Unity Catalog (от Databricks) и Nessie (от Dremio) не поддерживают востребованный в России протокол LDAP
Этот список можно продолжать долго.
Учитывая низкий уровень соответствия open-source каталогов потребностям российских пользователей, мы приняли решение создавать собственный каталог "с нуля". Определенную роль в этом сыграла и геополитика, которая все чаще становится причиной отказа мэйнтейнеров open-source проектов общаться с инженерами из России.
Возможности и планы
Первая версия CedrusData Catalog:
- Реализует спецификацию Iceberg REST API
- Имеет встроенную аутентификацию и базовую ролевую модель доступа
- Поддерживает файловые системы S3 и HDFS. В отличие от других каталогов, мы в первую очередь ориентируемся на поддержку on-premises хранилищ
- Хранит ваши метаданные в PostgreSQL или SQLite
- Имеет встроенный мониторинг и телеметрию (JMX, OpenMetrics, OpenTelemetry)
- Написан на Java 21 (возможно, стоило взять Scala?)
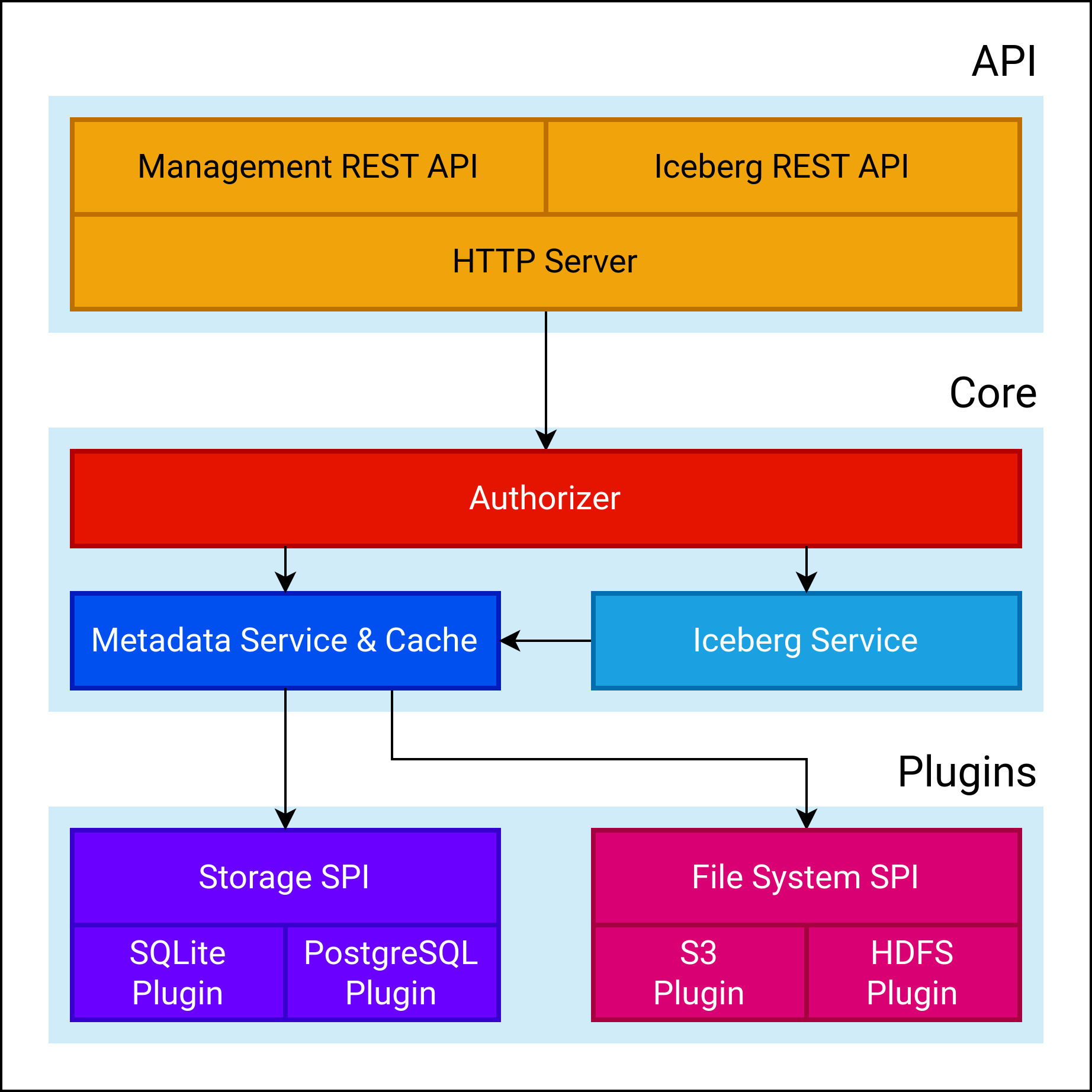
В первой версии нам было важно заложить устойчивый фундамент для быстрого наращивания функционала в будущем:
- Используем архитектуру плагинов, схожую с плагинами CedrusData и Trino, для быстрого подключения новых возможностей без риска дестабилизации ядра. Вероятно, мы вскоре опубликуем официальный API для разработки расширений
- Агрессивно кэшируем метаданные Iceberg. На горячем пути пользователя нет вызовов S3/HDFS/PostgreSQL и т.п.
- Подсистема безопасности аккуратно изолирована от API, чтобы в дальнейшем легко интегрировать расширенную ролевую модель и сторонние системы (LDAP, Ranger, и т.д.)
- Для увеличения тестового покрытия мы разработали специальный механизм, который позволяет использовать один и тот же код для тестирования всех пользовательских интерфейсов, будь то командная строка, HTTP запрос или embedded режим работы
В ближайшие два квартала мы собираемся добавить в каталог большое количество важного функционала: безопасность, high availability, автоматический maintenance таблиц Iceberg, статистики для акселерации запросов в CedrusData, Trino и Spark, и многое другое. Мы публикуем наши планы развития в документации, и будем рады услышать ваши пожелания и обратную связь через наш Телеграм-чат или специальный продуктовый опросник (ориентирован на занятых людей, у которых нет времени).
Как попробовать?
CedrusData Catalog можно запустить из дистрибутива или Docker-образа. Достаточно одной команды:
docker run -d --name example-catalog -p 9080:9080 \
cr.yandex/crpjtvqf29mpabhmrf1s/cedrusdata-catalog:458-1Мы подготовили для вас простые инструкции, для быстрого начала работы с различными движками. Вы сможете буквально за пять минут (может быть, десять-пятнадцать) поднять локально lakehouse с S3 или HDFS (!!!), нашим каталогом и одним из движков:
Предвосхищая вопрос про Apache Flink — обязательно добавим.
Протокол Iceberg REST быстро изменяется, поэтому где-то что-то может "не полететь". Например, в сообществе Iceberg недавно немного поломали совместимость REST протокола для виртуальных представлений, что расстроило некоторых пользователей последних версий Spark. Мы вовремя заметили эту проблему, и исправили ее до релиза. Но прогресс open-source неудержим, так что если вы столкнетесь с неожиданным поведением каталога, пишите нам в Telegram-чат, починим.
Удачного использования!