

Интеграция CedrusData c S3 на примере MinIO
MinIO это S3-совместимый object storage, который удобно использовать при тестировании и изучении работы CedrusData и Trino с озерами данных в S3. В данной статье приведена пошаговая инструкция по развертыванию MinIO на локальном компьютере и его интеграции с CedrusData.

Введение
MinIO это S3-совместимый object storage, который удобно использовать при тестировании и изучении работы CedrusData и Trino с озерами данных в S3.
В данной статье приведена пошаговая инструкция по развертыванию MinIO на локальном компьютере и его интеграции с CedrusData. Мы запустим MinIO в standalone режиме, настроим Hive Metastore и CedrusData для работы с S3 API, после чего выполним SQL-запросы из CedrusData к данным в MinIO.
Процесс развертывания занимает порядка 10-15 минут.
Данная инструкция так же доступна в документации CedrusData.
Что такое S3 API
В 2006 году компания Amazon запустила продукт Amazon S3, представляющий собой объектное хранилище (object storage) в облаке AWS. Пользовательские приложения работают с Amazon S3 через S3 REST API - набор команд, которые можно отправить через протокол HTTP.
Со временем конкуренты выпустили ряд собственных объектных хранилищ, которые так же поддерживают S3 REST API. Такимо бразом, S3 REST API де-факто является стандартным интерфейсом для работы с объектными хранилищами.
Для упрощения работы с S3-совместимыми объектными хранилищами был написан набор вспомогательных библиотек. Так, для выполнения операций над хранилищем из Java можно использовать библиотеку AWS Java SDK For Amazon S3, а для представления объектного хранилища в качестве файловой системы в экосистеме Hadoop была разработана файловая система S3AFileSystem.
Что такое MinIO
MinIO это популярное высокопроизводительное S3-совместимое объектное хранилище, которое может быть развернуто on-premise.
Возможность запуска on-premise позволяет использовать MinIO для тестирования и интеграции продуктов, работающих с S3 API.
Целевая конфигурация
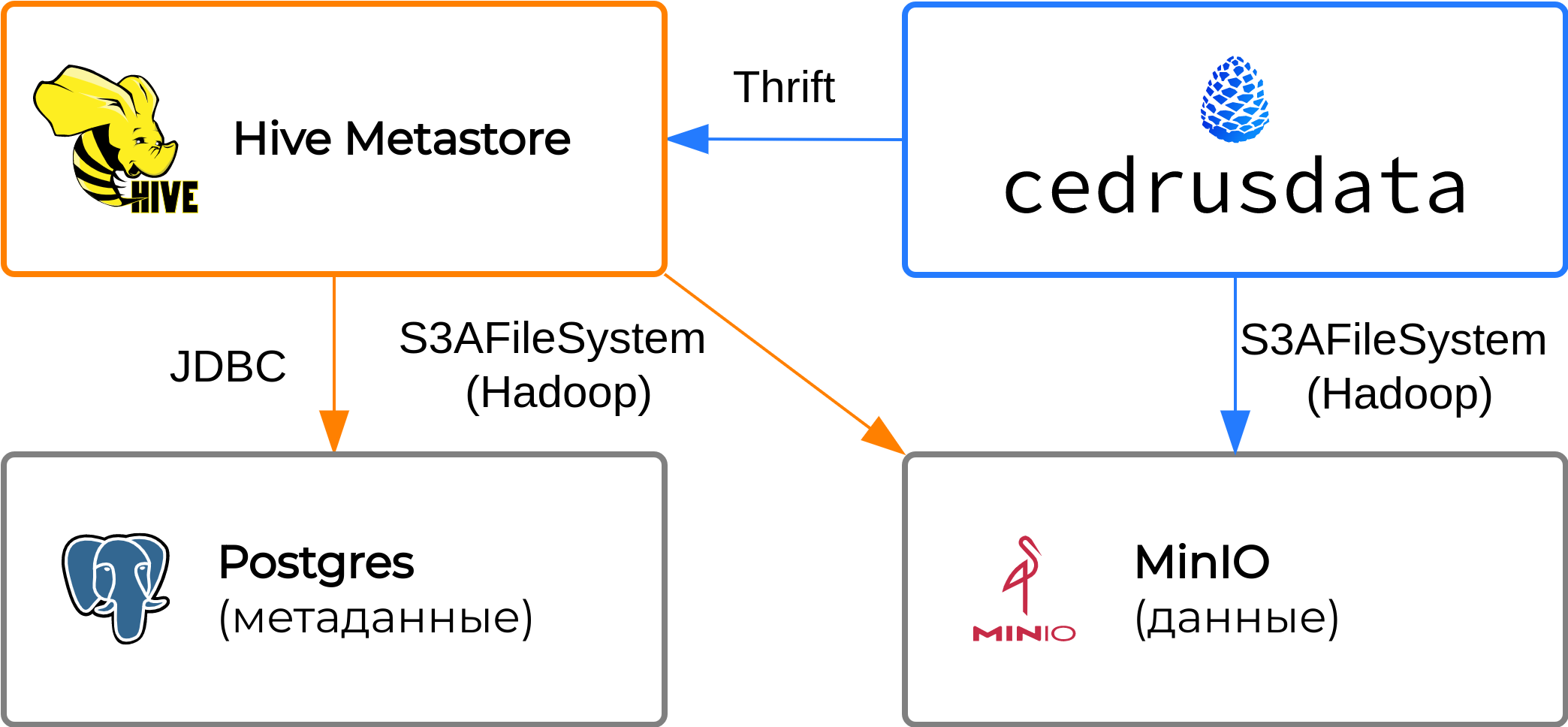
Наш пример состоит из следующих компонентов:
- Экземпляр MinIO, который хранит данные в локальной файловой системе.
- Экземпляр Hive Metastore, который хранит метаданные в Postgres, и работает с данными MinIO через S3 API.
- Узел CedrusData, который настроен на работу с указанными выше экземплярами MinIO и Hive Metastore.
Развертывание MinIO
Инструкции ниже приведены для операционных систем Ubuntu/Debian с использованием сетевых портов по умолчанию. Адаптируйте инструкции, если вы используете другую операционную систему, или если у вас возникает конфликт портов.
Шаг 1. Создайте локальную директорию, в которой будут храниться данные MinIO. Владельцем директории должен быть пользователь, от имени которого будет запущен MinIO. В данном примере мы создаем директорию `/home/minio` и меняем владельца на текущего пользователя.
Шаг 2. Скачайте сервер MinIO и установите executable флаг:
Шаг 3. Запустите сервер MinIO. Сервер будет доступен на порту `9000`. Поменяйте порт при необходимости. В команде ниже мы задаем имя и пароль root пользователя, которые будут в дальнейшем использованы как access key и secret key, соответственно. При промышленном использовании MinIO, имя и пароль root пользователя обычно используются администраторами, а конечные пользователи получают индивидуальные ключи с необходимым уровнем доступа.
Шаг 4. Скачайте клиент MinIO и настройте его для работы с запущенным сервером:
Шаг 5. Создайте в MinIO bucket с именем `mybucket`:
Шаг 6. Убедитесь, что в директории `/home/minio` появилась директория `mybucket`:
Процесс развертывания MinIO завершен.
Конфигурация Hive Metastore
Для выполнения дальнейших шагов необходимо развернуть Hive Metastore и CedrusData согласно инструкции Развертывание Hive Metastore.
Что бы Hive Metastore мог работать с S3 API, необходимо добавить ряд библиотек и предоставить конфигурацию файловой системы `S3AFileSystem`.
Шаг 1. Добавьте в Hive Metastore библиотеки для работы с S3:
Шаг 2. В директории дистрибутива Hive Metastore добавьте следующее содержимое в файл `conf/metastore-site.xml`. В данном примере мы работаем с MinIO через протокол `http`. Это сделано для простоты. При промышленном использовании следует использовать протокол `https`.
Шаг 3. Из директории дистрибутива Hive Metastore перезапустите Hive Metastore. Убедитесь, что переменные окружения `JAVA_HOME` и `HADOOP_HOME` заданы.
Процесс конфигурации Hive Metastore завершен.
Конфигурация CedrusData
Что бы CedrusData мог работать с S3 API, необходимо добавить параметры S3 в конфигурацию Hive коннектора.
Шаг 1. В директории дистрибутива CedrusData добавьте следующее содержимое в файл `etc/catalog/hive.properties`. В данном примере мы работаем с MinIO через протокол `http`. Это сделано для простоты. В реальных сценариях следует использовать протокол `https`.
Шаг 2. Из директории дистрибутива CedrusData перезапустите узел:
Процесс конфигурации CedrusData завершен.
Проверка работы MinIO с CedrusData
На данном этапе у вас должны быть запущенны MinIO, Hive Metastore и узел CedrusData.
Шаг 1. Из директории дистрибутива CedrusData выполните следующие команды, что бы создать таблицу `call_center`, и наполнить ее данными в формате Parquet:
Шаг 2. Убедитесь, что в директории `/home/minio` появились новые директории и файлы:
Шаг 3. Из директории дистрибутива CedrusData выполните следующую команду для чтения данных из таблицы `call_center`:
Шаг 4. Из директории дистрибутива CedrusData выполните следующие команды для удаления таблицы и схемы:
Шаг 5. Убедитесь, что соответствующие файлы и директории удалены из `/home/minio`:
Следующие шаги
В данной статье мы развернули экземпляр MinIO и настроили Hive Metastore и CedrusData для работы с S3-совместимым объектным хранилищем.
Вы можете продолжить знакомство с возможностями CedrusData по работе с озерами данных с помощью документации Hive коннектора и других руководств.
Мы так же рекомендуем вам ознакомиться с расширенными инструкциями по настройке безопасности MinIO и Trino.