

Релиз CedrusData 422-1
Улучшения в Iceberg коннекторе и расширенная интеграция с LDAP

Общая информация
Релиз CedrusData 422-1 вышел 25 августа 2023 года и основан на Trino 422.
Запуск из архива:
Запуск в Docker-контейнере:
Ключевые изменения
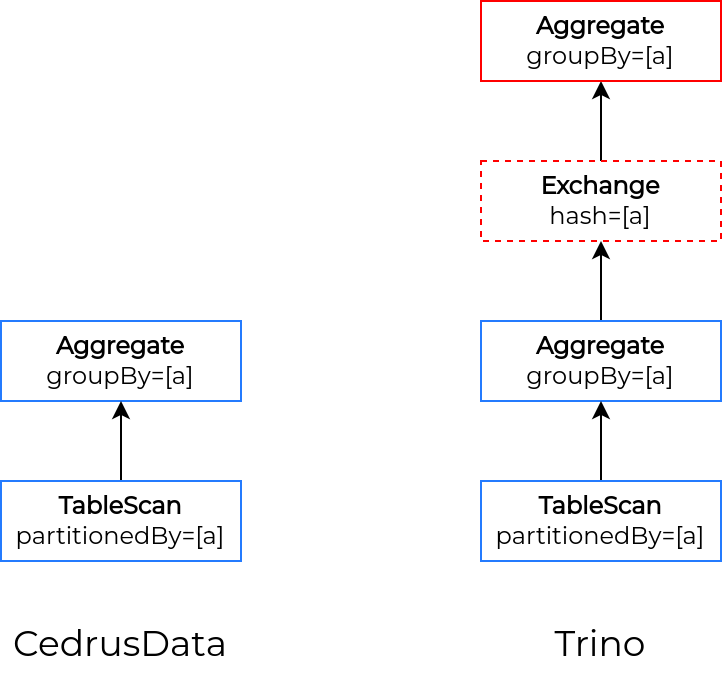
Ускорение запросов к partitioned таблицам Iceberg
Документация: https://docs.cedrusdata.ru/latest/connector/iceberg.html#iceberg-partitioned-execution
Мы добавили в Iceberg коннектор возможность предоставлять оптимизатору информацию о партиционировании таблиц. Это позволяет оптимизатору реже использовать операторы `Exchange` при работе с партиционированными таблицами. Например, следующий запрос в CedrusData может быть выполнен без `Exchange`, если ключ партиционирования таблицы совпадает с ключем группировки:
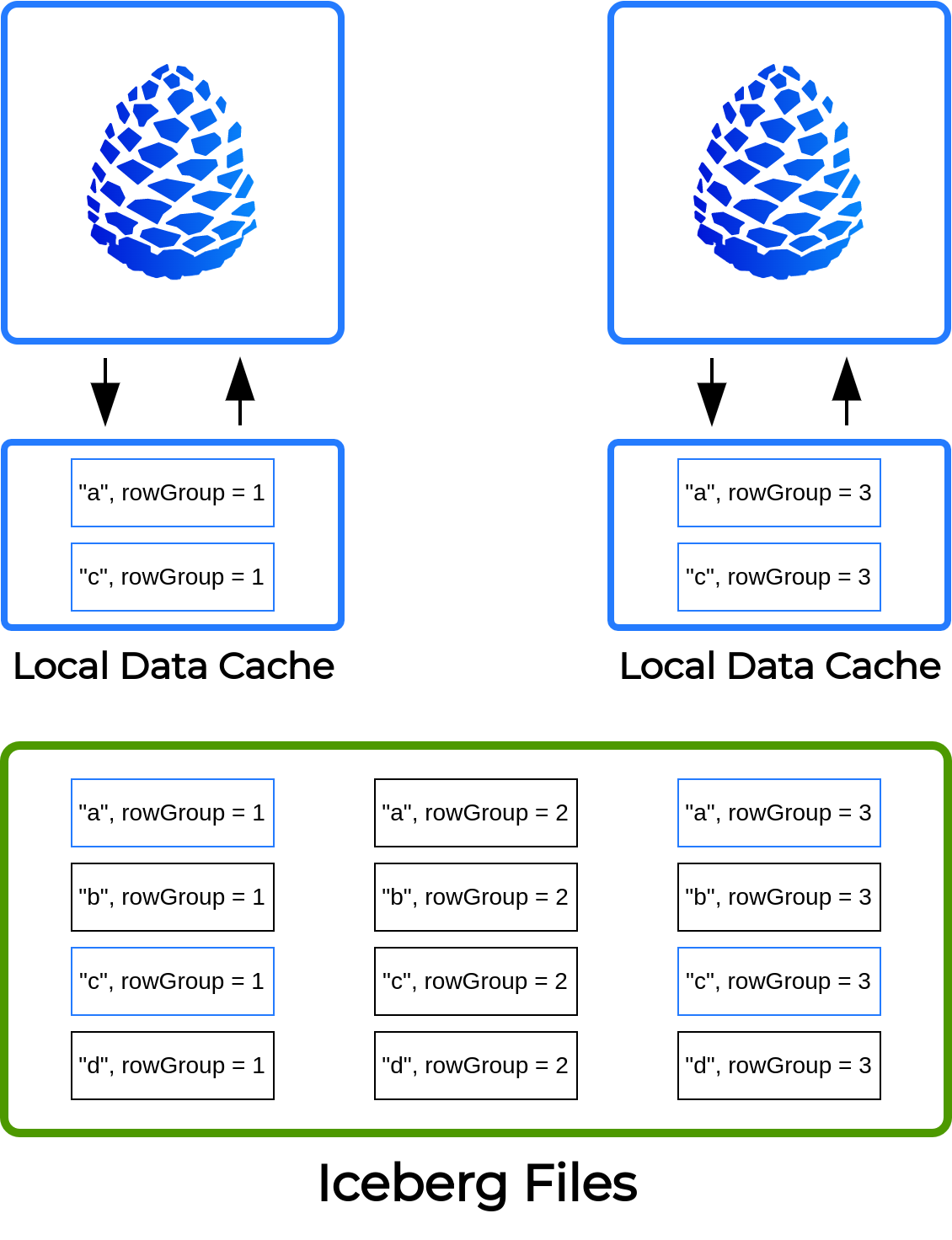
Локальный дисковый кэш данных для Iceberg
Документация: https://docs.cedrusdata.ru/latest/connector/iceberg.html#iceberg-data-cache
В версии 417-1 мы добавили локальный дисковый кеш для Hive коннектора. В версии 422-1 вы можете использовать данный кэш и в Iceberg коннекторе. Для этого необходимо указать в конфигурации коннектора путь к директории, в которой будут сохранены закешированные данные.
Получение групп пользователей из LDAP
Документация: https://docs.cedrusdata.ru/latest/security/group-ldap.html
Trino имеет встроенную возможность аутентификации пользователей на основе LDAP. В данном релизе мы добавили возможность использования LDAP для получения списка групп пользователя. Группы могут быть использованы для более удобного управления правами доступа.

Дальнейшие планы
Наша команда сосредоточена на финализации важного изменения ядра Trino, которое позволит переиспользовать результаты выполнения повторяющихся подзапросов. Кроме того, мы добавляем в коннектор Greenplum возможность чтения данных таблиц напрямую с сегментов, минуя координатор. Мы так же завершаем интеграцию CedrusData с Apache Ranger. Наконец, мы начали работу над новым UI, который даст возможность пользователям запускать SQL запросы к CedrusData, а администраторам удобно управлять кластером.
Свяжитесь с нами, что бы узнать больше о CedrusData и Trino.