

Массивно-параллельная обработка запросов в Trino
Как Trino обеспечивает быстрое выполнение запросов с помощью массивно-параллельной архитектуры

Введение
Основная задача аналитических SQL-движков — быстрая обработка больших объемов информации. Для этого аналитические системы стремятся задействовать все доступные вычислительные мощности. В данной статье мы обсудим, как Trino использует принципы массивно-параллельной обработки для обеспечения высокой производительности выполнения SQL-запросов.
В качестве примера мы будем рассматривать выполнение SQL-запроса к файлам в формате Apache Parquet в озере данных. Parquet — это популярный колоночный формат хранения данных. Отдельный файл Parquet хранит некоторое количество записей. Большие наборы данных обычно организованы в несколько файлов Parquet. Аналитические движки, например Trino или Apache Spark, рассматривают совокупность файлов Parquet как единую логическую "таблицу".
Рассмотрим выполнение следующего SQL-запроса (схема TPC-DS):
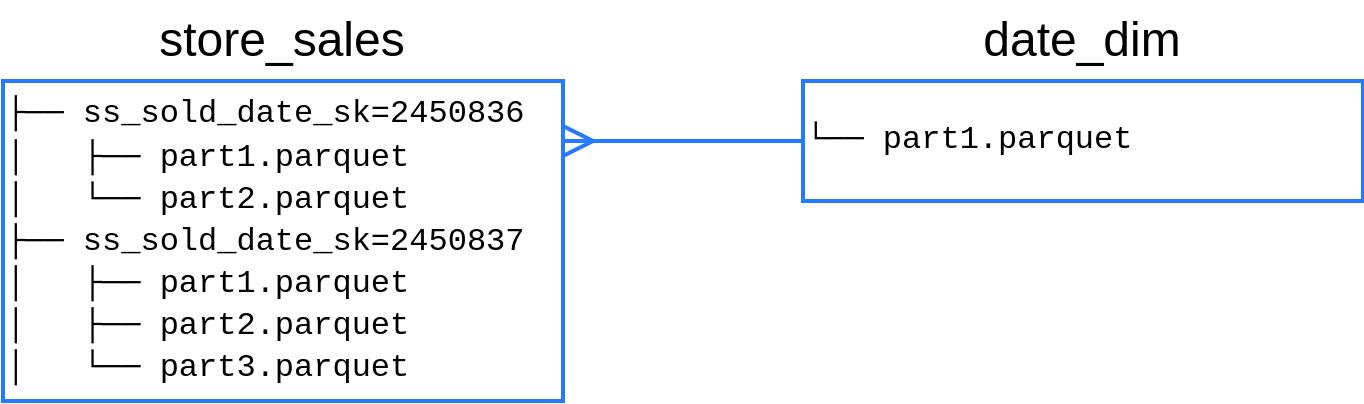
В данном запросе мы считаем объем продаж по месяцам для определенного клиента, соединяя таблицу фактов `store_sales` со справочником `date_dim`. Таблица `store_sales` представляет собой большое количество файлов Parquet, партиционированных по дате. Таблица `date_dim` представлена единственным файлом Parquet.
Вертикальный параллелизм
Распределенные SQL-движки выполняют запросы, задействуя несколько узлов. Для выполнения некоторых операций узлы должны обмениваться друг с другом промежуточными результатами. Например, для выполнения операции агрегации необходимо убедиться, что все записи с одними и теми же значениями атрибутов `GROUP BY` оказались на одном узле. Для организации выполнения распределенного запроса планировщик движка анализирует, какое распределение данных необходимо конкретным операторам, и вставляет специальные операторы `Exchange`, которые перераспределяют данные в кластере по мере необходимости. Подробнее про операторы Exchange можно почитать в нашем блоге.
Начальный план запроса в Trino для нашего запроса будет выглядеть следующим образом:
За расстановку операторов `Exchange` в Trino отвечает правило AddExchanges, которое определяет требования операторов к распределению входящего потока данных, и вставляет `Exchange` там, где требуемое и текущее распределения не совпадают. План запроса после работы правила `AddExchanges`:
Следует отметить, что в общем случае существует несколько допустимых расстановок `Exchange` для конкретного SQL-запроса. Стоимость выполнения планов с разными расстановками `Exchange` может сильно варьировать, а значит нам нужна cost-based оптимизация. В текущей реализации Trino расставляет операторы `Exchange` эвристически без рассмотрения альтернативных планов, а потому может выбирать неоптимальные планы. В CedrusData мы разработали новый cost-based оптимизатор на основе алгоритма Cascades, который рассматривает несколько вариантов расстановки `Exchange` и выбирает наиболее оптимальный план на основе оценки стоимости.
Далее Trino разбивает план запроса на фрагменты по границам `Exchange` таким образом, что каждый фрагмент имеет один "выход" и один или несколько "входов" (таблица или другой фрагмент). План после разбиения на фрагменты (см. PlanFragmenter):
Полученные фрагменты могут быть выполнены независимо друг от друга. Так, сканирование таблицы `store_sales` во втором фрагменте может происходить параллельно со сканированием таблицы `date_dim` в первом. Третий фрагмент зависит от результатов второго, но и он может осуществлять финальную агрегацию параллельно по мере получения результатов от второго фрагмента.
Исторически Trino использовал наивный алгоритм планирования параллелизма фрагментов, который безусловно запускал все фрагменты параллельно. Подобная стратегия плохо работает в ряде случаев, так как множество фрагментов начинают конкурировать за ограниченные ресурсы кластера (сеть, CPU, RAM). Например, это особенно актуально для динамических фильтров, про которые мы подробно поговорим в другой раз.
Сейчас Trino использует так называемый phased алгоритм. Данный алгоритм старается отложить выполнение тех фрагментов, которые с большой вероятностью будут заблокированы ожиданием результатов от дочерних фрагментов. В большинстве случаев это приводит к ускорению запросов: дочерние фрагменты сталкиваются с меньшей конкуренцией за ресурсы, быстрее завершают свою работу, а следовательно быстрее разблокируют родителей.
Параллельное чтение данных
Второй важнейший источник параллелизма в Trino — чтение данных. SQL запросы обычно содержат операции сканирования одной или нескольких логических таблиц из различных источников данных. В случае озера данных "таблицей" является один или несколько файлов.
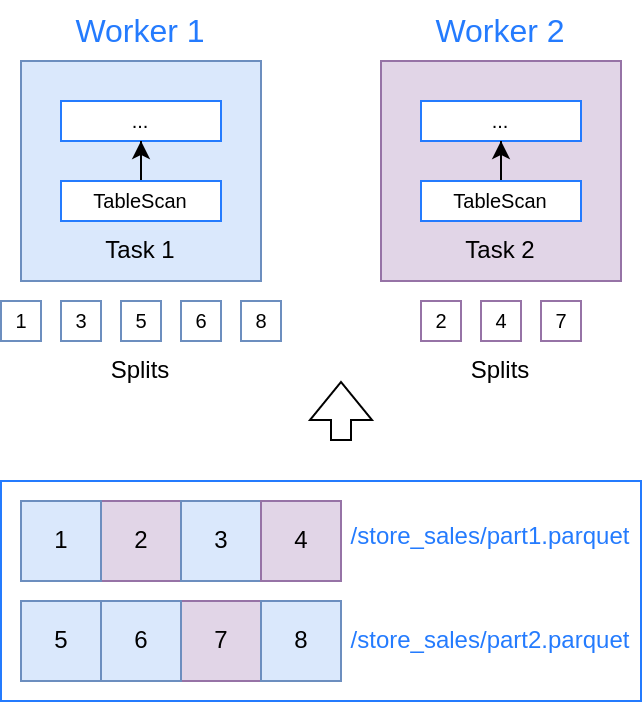
Во многих случаях существует возможность параллельного сканирования таблицы из нескольких потоков. Например, каждый поток может читать отдельный файл или его часть. В Trino чтение части данных таблицы представлено абстракцией Split. В процессе анализа запроса Trino обращается к метаданным источника через специальный SPI, что бы получить список сплитов для конкретной таблицы. Чем больше сплитов можно выделить для таблицы, тем выше максимально возможный уровень параллелизма.
Логика разбиения таблицы на сплиты зависит от типа источника. Рассмотрим второй фрагмент, в котором происходит чтение большой таблицы `store_sales`, состоящей из нескольких файлов Parquet. Сначала Trino обращается к Hive Metastore и файловой системе озера (HDFS, S3, и т.п.) для получения списка файлов таблицы. В простейшем случае одному сплиту будет соответствовать один файл. Если конкретный файл является достаточно большим, имеет смысл разбить его на несколько непересекающихся диапазонов. В таком случае, для одного файла может быть создано несколько сплитов. В Trino за выбор размера сплита в озере данных отвечают параметры `hive.max-initial-split-size` и `hive.max-split-size`. По умолчанию, Trino будет стремиться разбить файл на сплиты размером от 32 до 64 мегабайт. Например:
Разбиение файла на части может не соответствовать его внутренней структуре, поэтому в процессе обработки сплита Trino корректирует границы чтения. Например, смещение в 32Mb почти никогда не будет совпадать с реальной границей row group Parquet, поэтому Trino сдвигает диапазон чтения файла в соответствии с реальным смещением ближайшей row group.
В общем случае таблица может состоять из тысяч файлов, поэтому получение списка сплитов является асинхронным процессом. По мере получения метаданных Trino начинает рассылать запросы на обработку сплитов по узлам. При этом Trino отслеживает текущее состояние узлов и стремится распределить сплиты равномерно. Это позволяет Trino избегать ситуаций "hot partition", характерных для shared-nothing систем вроде Greenplum, когда неравномерность распределения нагрузки по партишенам (например, разные размеры партишенов или особый интерес пользователей к данным из конкретного партишена) приводит к перегрузке отдельных узлов.
Локальный параллелизм
Фрагмент — это шаблон, содержащий последовательность операторов. Некоторые операторы фрагмента могут быть блокирующими. Оператор называется блокирующим, если он может произвести первый результат только после получения всех входных данных от дочернего оператора. Примером такого оператора является построение хэш-таблицы для выполнения hash join. Trino предварительно разбивает фрагмент по границам блокирующих операторов на отдельные пайплайны (pipeline). Например, второй фрагмент в нашем запросе может быть разбит на два пайплайна:
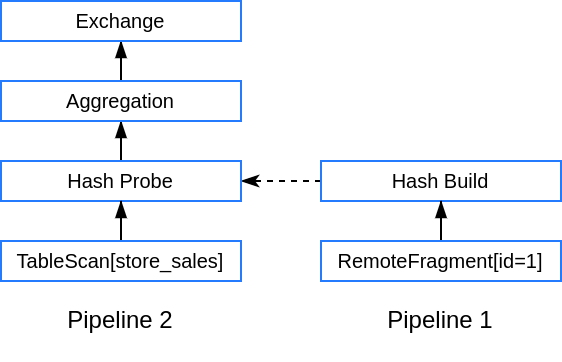
После получения задачи на обработку сплита, узел определяет, какому пайплайну принадлежит сплит. Далее Trino создает исполняемый экземпляр пайплайна, называемый драйвер (Driver), и ставит его в очередь на исполнение. Таким образом, в рамках одного узла Trino может одновременно выполнять несколько драйверов, которые представляют разные пайплайны, разные фрагменты и разные запросы.
Некоторые драйвера могут требовать значительно больше времени для обработки своего сплита, чем другие. Поэтому Trino необходимо управлять порядком запуска драйверов и временем их работы. Для определения порядка запуска драйверов Trino использует многоуровневую priority queue (MultilevelSplitQueue). Для каждого драйвера происходит подсчет суммарного времени выполнения. По мере того как драйвер накапливает время, он последовательно перемещается между уровнями очереди: от нулевого к четвертому. Планировщик стремится распределить время выполнения таким образом, чтобы драйвера на нулевом уровне получали в среднем в два раза больше времени, чем драйвера на первом уровне, в четыре раза больше времени, чем драйвера на втором уровне, и т.д. Мультипликатор можно изменить с помощью параметра конфигурации `task.level-time-multiplier`. Таким образом, Trino отдает предпочтение более "легким" запросам, но в то же время и длительные запросы гарантированно рано или поздно получат свой квант времени.

Выбор очередного драйвера для исполнения состоит из двух шагов:
- Определить уровень, который должен получить следующий квант процессорного времени.
- Взять из выбранного уровня драйвер, который до сих пор получил наименьшее количество процессорного времени.
После того как драйвер выбран, начинается его выполнение. Планировщик отводит драйверу квант времени, равный одной секунде. Если квант времени истек (см. DriverYeildSignal), или драйвер не может продолжать свое выполнение (например, закончились входные данные или заполнен output buffer), выполнение драйвера останавливается, и он снова попадает в очередь на исполнение. Таким образом, блокировка драйвера не приводит к снижению общей пропускной способности узла.
Процесс повторяется до тех пор, пока драйвер не завершит обработку сплита. Квантование времени позволяет Trino гарантировать (с поправкой на непредсказуемые блокирующие операции чтения из источника), что один или несколько тяжелых запросов не смогут надолго заблокировать прогресс конкурентных задач.
Выводы
Массивно-параллельная архитектура (MPP) позволяет Trino задействовать доступные вычислительные ресурсы для эффективного выполнения запросов. К основным методам обеспечения параллелизма в Trino относятся:
- Вертикальный параллелизм выполнения запроса за счет разбиения на фрагменты.
- Вертикальный параллелизм выполнения фрагмента на узле за счет разбиения на пайплайны.
- Горизонтальный параллелизм выполнения пайплайнов за счет разбиения данных таблицы на сплиты, обрабатываемые драйверами.
- Локальный scheduler, который параллельно выполняет множество драйверов.
В следующей статье мы подробно рассмотрим реализацию одной из важнейших оптимизаций в Trino, без которой даже MPP не сможет обеспечить приемлемую производительность — динамические фильтры. До встречи!