

Новости
9 октября 2025
CedrusData это распределенная SQL-система для создания аналитических платформ уровня предприятия на основе open-source проекта Trino. Работает с любыми источниками и объемами данных, в облаке и on-premise.
Разрабатывается компанией Querify Labs.
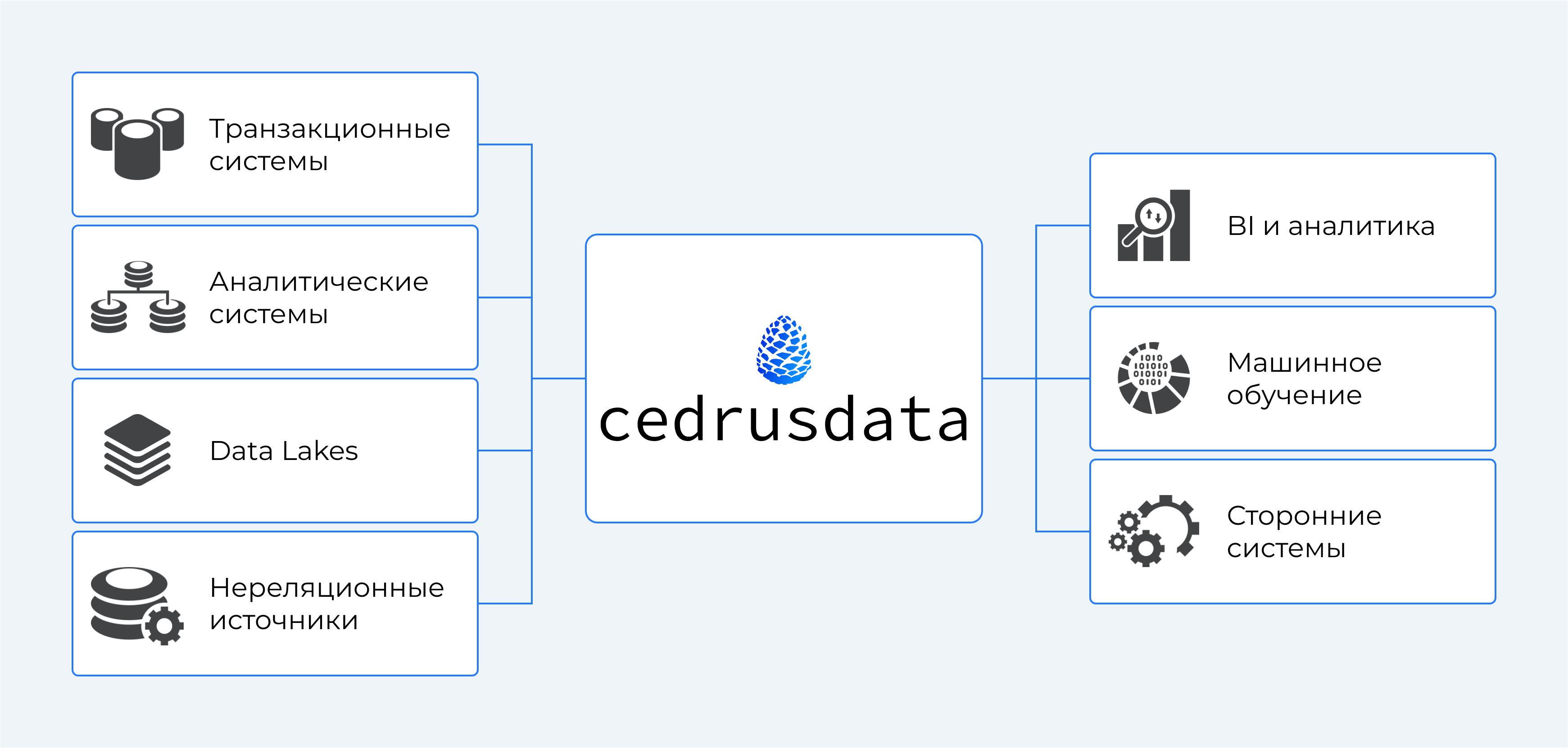
CedrusData является центральным компонентом современных аналитических архитектур lakehouse и data fabric.

Анализируйте данные, подключайте BI платформы, и создавайте интеграции с другими системами с помощью ANSI SQL. Минимум кастомного кода.

Проверенная технология, которая используется ведущими мировыми технологическими компаниями и обеспечивает высочайшую производительность на масштабах до сотен петабайт.

Разделение compute и storage и нативная интеграция с Kubernetes позволяют быстро проверять гипотезы, и итеративно внедрять новый функционал в рамках существующей инфраструктуры.

Уменьшайте количество копий данных и переносите нагрузку из дорогих в поддержке систем в дешевые файловые хранилища без потери функционала и производительности.

Cedrus работает с открытыми форматами данных, предотвращая vendor lock-in, и обеспечивая доступ к данным предприятия из различных систем без усложнения инфраструктуры.

Внедряйте новые сценарии анализа данных из существующих систем с помощью федеративной модели выполнения запросов.
CedrusData позволяет выполнять сложные операции над данными из разных источников без изменений существующей инфраструктуры. Используйте новые возможности интеграции существующих систем для построения data fabric и data mesh платформ, и упрощения доступа к данным в масштабах всей организации.


CedrusData является ключевым компонентом для построения современных lakehouse архитектур. Интеграции с Hive Metastore и Apache Iceberg обеспечивают управление метаданными вашего data lake, а подсистема кэширования гарантирует высокую производительность при чтении сырых данных.
CedrusData отделяет выполнение запросов от хранения данных. Это позволяет вам создавать множественные вычислительные кластеры и эластично их масштабировать без перемещения данных и создания дополнительных копий. Federated модель выполнения дает возможность перераспределять нагрузку из более дорогих аналитических систем в пользу дешевых файловых хранилищ.



Мы рассказываем про внутреннее устройство CedrusData, Trino и других систем обработки данных.


